Opening Data
OpenTech 2008
July 5th 2008
Rufus Pollock
[open knowledge foundation]
[http://www.okfn.org/]
About the Foundation

Founded 2004 / Not-for-profit / A variety of projects
KnowledgeForge, CKAN, Open Shakespeare, Open Economics ...
What is Open Knowledge?
http://www.opendefinition.org/
Content/Data/Information (Genes to Geodata, Stats to Sonnets)
Open = Freedom to Access / Use / Re-use / Redistribute
So How's This Relevant
After all Openness isn't an End-in-Itself!
What We'd Like to be Able To Do
Understand and Create
Whether I'm a fund-manager making investments
or
An academic looking to cure cancer
Sure, but Specifically By
Having Lots of Material
AND
Plugging It Together
Getting Material (in a nice form) is Often Non-Trivial
US Unemployment
But the Original Data Ain't So Nice
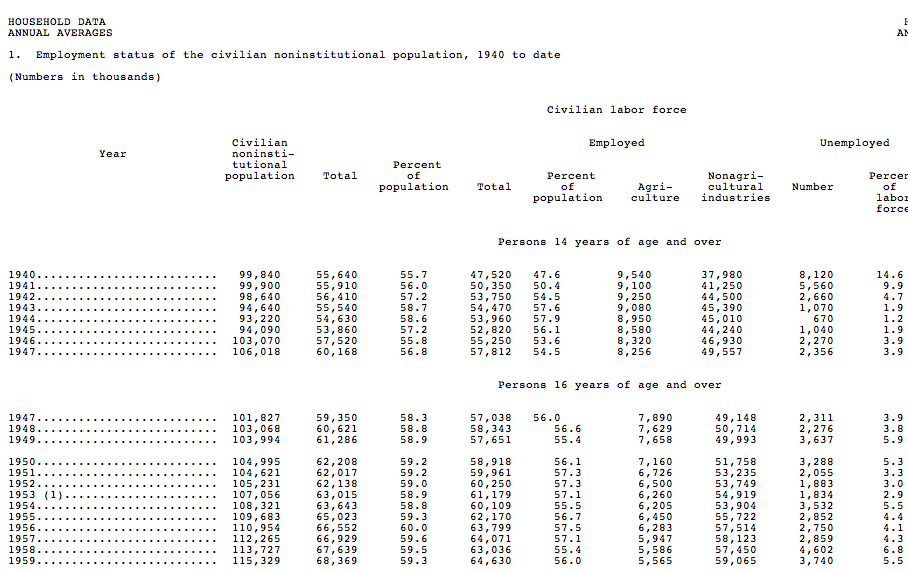
So We Clean It ...
http://knowledgeforge.net/econ/svn/trunk/data/bls/10864a10-2873-4b4c-bd38-82b9e5297a25/data.py
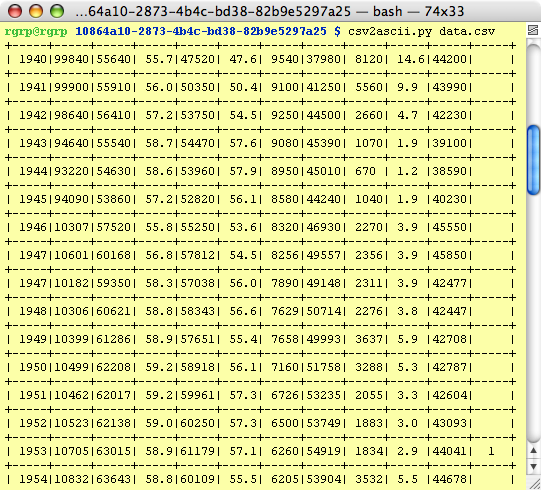
So I've now created/parsed a whole bunch of data
Which I can Happily Use
US Unemployment Figures: 1940-2006
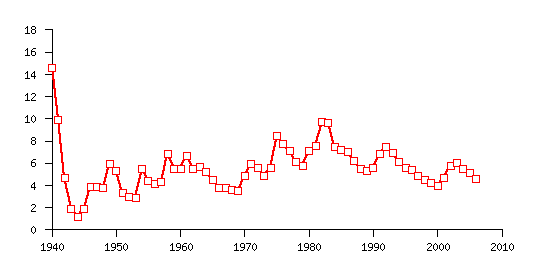
OK, that's great: But What About Reuse
Maybe I want to link this with loan defaults, interest rates ...
The Many Minds Principle
The Coolest Thing To Do With Your Material Will Be Thought of By Someone Else
Long version: The set of useful things one can do with a given informational resource is always larger than can be done (or even thought of) by one individual or group.
So We Should Make it Available - Upload the Material Somewhere
One Ring to Rule Them All
- Everyone everywhere uploads to some central repository
- Using the same metadata formats
- Using the same data formats
NO!
The Revolution Will be Decentralized
Small Pieces, Loosely Joined
Production Should Be Decentralized and Federated
How Do We Make This Happen
How Do We Support Decentralization of Creation
AND
Recombination of the Produced Material
Consider the Miracle of 'apt'
Componentization
Atomization and Packaging
Componentization is the process of atomizing (breaking down) resources into separate reusable packages that can be easily recombined.
NB: If the Data is OPEN
Putting Humpty-Dumpty Back Together is Much Easier
(And Clear Openness 'Standard' Matters)
2 Related but Distinct Aspects
Knowledge APIs + (Automated) Discovery and Installation
Ignore Knowledge APIs Here (Hard!)
- Domain Specific
- Require Coordination
- Hard to Plan in Advance, Progress By Experimentation
Automated Discovery and Installation
- Wrap the material up and make it available
- In a form suitable for automatable downloading
- Basic metadata: id, license, etc
- Register so it can be found ...
Automated Installation: datapkg
http://www.okfn.org/datapkg/
Creating
datapkg create mypkg
# go into mypkg and add some data
cp ~/mydata1.csv ./
# edit the metadata
vi setup.py / vi metadata.txt
# tar it up and upload it somewhere
scp -r . http://somesite.com/downloads
# or register on CKAN
datapkg register .
Where to Register?
CKAN: http://www.ckan.net/
Freshmeat/CPAN/... for Open Data/Knowledge
Getting and Using
# later and somewhere else ...
datapkg install mypkg
# or just
datapkg install http://somesite.com/donwloads/mypkg.tgz
datapkg list-installed
# USING
# in my code
import datapkg
data = datapkg.resource_stream('mypkg-name', 'mydata1.csv')
# plot it etc
# datapkg plot ...
The Start of the 'Debian of Data'
Thank-You
Rufus Pollock
rufus.pollock@okfn.org
http://www.ckan.net
http://www.okfn.org/datapkg/
(later today)