Open Data and Componentization
XTech 2007
Jo Walsh and Rufus Pollock
[open knowledge foundation]
[http://www.okfn.org/]
What We'd Like to be Able To Do
Understand Things
Sure, but Specifically By
Having Lots of Data
AND
Plugging It Together
Having Lots of Data (in a nice form) is Non-Trivial
What Were Governments Up to Before WWI?
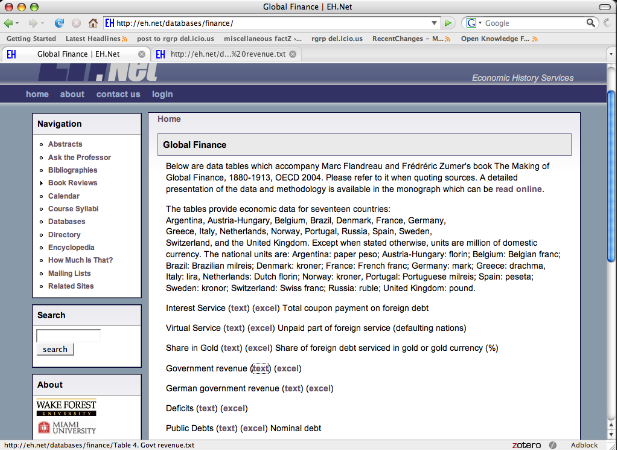
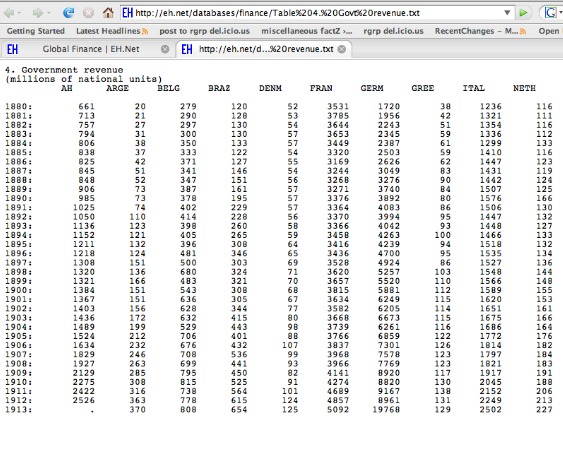
The Cleaned Data
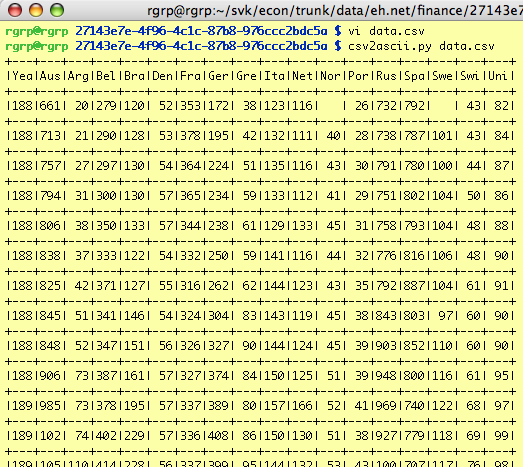
It's Not Always So Simple
So I've now created/parsed a whole bunch of data
Which I can Happily Use
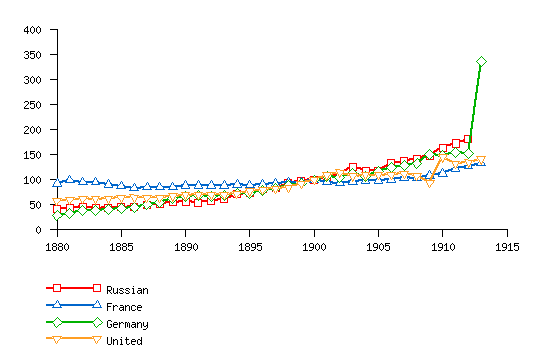
Government Revenue 1880 - 1914 (1900=100)
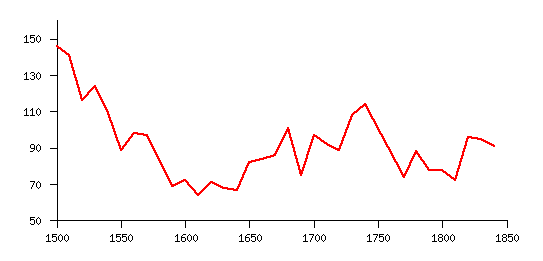
UK Real Wages 1500-1850
OK, that's great: But What About Reuse
The Many Minds Principle
The Coolest Thing To Do With Your Data Will Be Thought of By Someone Else
Long version: The set of useful things one can do with a given informational resource is always larger than can be done (or even thought of) by one individual or group.
So We Should Make it Available - Upload the Data Somewhere
- http://www.openeconomics.net/
- http://www.swivel.com
- http://www.freebase.com/
One Ring to Rule Them All
- Everyone everywhere uploads to some central repository
- Using the same metadata formats
- Using the same data formats
NO!
The Revolution Will be Decentralized
Small Pieces, Loosely Joined
Production Should Be Decentralized and Federated
How Do We Make This Happen
How Do We Support Decentralization of Data Creation
AND
Recombination of the Produced Data
Consider the Miracle of 'apt'
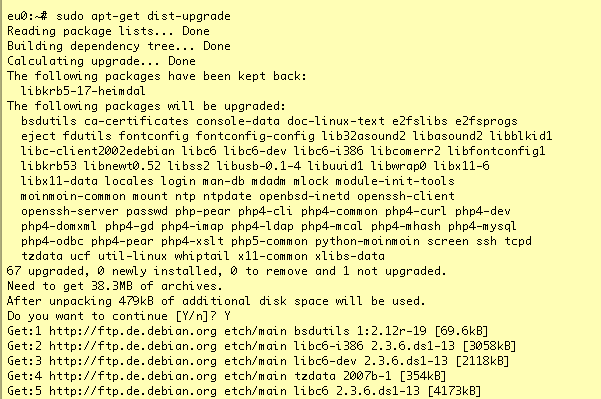
Componentization
Atomization and Packaging
Componentization is the process of atomizing (breaking down) resources into separate reusable packages that can be easily recombined.
Atomization
- Break Things Down into Suitable Sized Chunks
- Not all of us want all 70TB of CO2 data
Packaging
- Add an external interface (knowledge API)
- Otherwise we can't put humpty-dumpty back together again
- Allow Divide and Conquer to Work
Knowledge APIs
- Identifiers
- Standards
- Web APIs (but we still want the dump)
- Code itself (distinction between code and data will disappear)
Some Examples
Human Genome Project
- Social value of decentralized collaboration
- Knowledge APIs: Unique identifiers for genes
- Very large amounts of semi-versioned data
Scholarly Publication
- The API: unique identifiers (DOI, standard terms H20)
- Academic papers offer limited level of reuse and recombination
- Not easily atomizable
Geodata
- Open Street Map: One Ring to Rule Them All?
- What are the Standards which will form the APIs
- How do we scale and decentralize?
So Where Do We Start
We Can't Do All of This Right Now
The APIs (the entry points) Are the Most Difficult Thing
We Can Only Progress By Experimentation
We Can At Least Wrap the Data Up
- In a Form Suitable for Automatable Downloading
- Include the build scripts (how did you get from source to here)
- datapkg ...
mkdir my_new_distribution
cd my_new_distribution
datapkg wrap mydata.csv mydata2.csv ...
# edit the metadata
vi config.txt
# register
datapkg register
# somewhere else ...
easy_install datapkg
datapkg install econdata
# in my file
import datapkg
data = datapkg.load('econdata', 'mydata1.csv')
plot(data)